|
.NET Based OPC UA Client/Server SDK
2.6.1.422
|
|
.NET Based OPC UA Client/Server SDK
2.6.1.422
|
In the old days the classic DA Server have used simple “string”-Identifiers. The so called “ItemID” was a fully qualified name that was unique throughout the whole server (there was only one “namespace”). Furthermore, the classic DA Servers had only capabilities for a simple hierarchy, i.e. a tree-like structure with branches and leaves. Hence, many vendors have used the full folder hierarchy to create unique ItemIDs (e.g. “Folder1.Folder2.Folder3.MyTemperature”). This lead to massive redundant strings, wasting memory and slowing down performance when looking up or searching for individual Items. With OPC UA, this concept has been abandoned.
In OPC UA, every entity in the address space is a node. To uniquely identify a Node, each node has a NodeId, which is always composed of three elements:
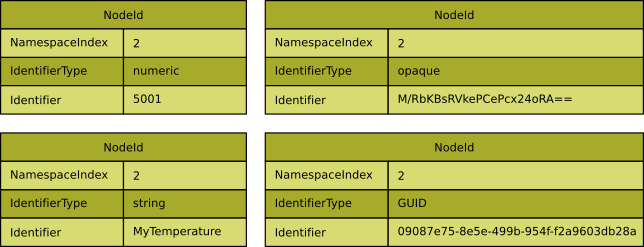
The following image shows examples for NodeIds having different identifier types.
There is an XML notation defined by the OPC UA XML Schema which represents a fully qualified NodeId. The format of the string is:
ns=<namespaceIndex>;<identifiertype>=<identifier>
with the fields
A flag that specifies the identifier type. The flag has the following values:
| Flag | Identifier Type |
|---|---|
| i | NUMERIC (UInteger) |
| s | STRING (String) |
| g | GUID (Guid) |
| b | OPAQUE (ByteString) |
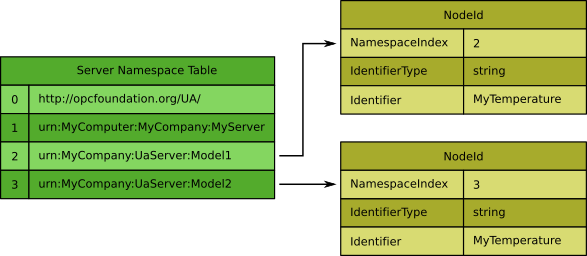
The identifier part of a NodeId uniquely identifies a node within a namespace, but it is possible that the same identifier is used in different namespaces for different nodes. Hence only the namespace plus the identifier forms a fully qualified identifier (see figure below). This means if a client requests a node, e.g. in a read service, it not only needs the identifier, but also the namespace the node belongs to.
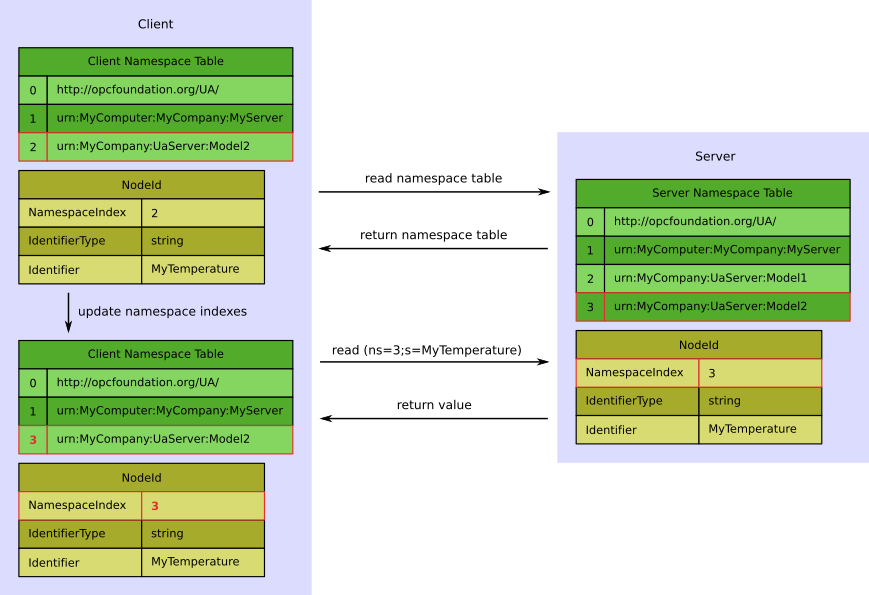
In OPC UA service calls the namespace index is used instead of the longer namespace URI in NodeIds. The Client needs to take care of the correct mapping from namespace URI to namespace index. Servers are not allowed to change the namespace index for a specific namespace URI or delete entries from the namespace table as long as an active session exist, so that clients can cache the namespace table for a specific session. But a Server may change namespace indexes and remove entries from the namespace table if no Client is connected or if the server is restarted. For this reason, a Client should not persist the namespace index without storing the namespace URI as well, because a namespace URI represented by index “2” during one session could be represented by index “5” during the next session. Thus, when having established a session with a Server, a Client should always read the Server’s namespace table and update namespace indexes before calling services in which NodeIds are involved.
The following figure shows a typical procedure a Client follows when reading atrributes of a node. In this example, the client wants to read the Node represented by the identifier “MyTemperature” which belongs to the namespace identified by the URI “urn:MyCompany:UaServer:Model2”. The client stores an own namespace table containing the URIs it is interested in to build up fully qualified NodeIds, but doesn’t yet know the corresponding namespace index in the Server namespace table. For being able to access the correct Node, the client has to read the Server namespace table first. The namespace URI “urn:MyCompany:UaServer:Model2” is represented by namespace index “3” on the Server. Now the client is able to update the namespace indexes in its own namespace table and the NodeId it wants to access (in our example this means replacing index “2” with index “3”) and has all information that is needed to access the correct node, in our example “ns=3;s=MyTemperature” in XML notation. As it is allowed that the namespace identified by the URI “urn:MyCompany:UaServer:Model1” also contains a Node having the identifier “MyTemperature”, the client may not even notice that it accessed the wrong node when reading “ns=2;s=MyTemperature”.