 |
High Performance OPC UA Server SDK
1.1.1.177
|
|
High Performance OPC UA Server SDK
1.1.1.177
|
The SDK contains two tools for address space generation from XML NodeSet file.
To understand the possibilities and restrictions if the SDK's address space model, it is necessary to first understand the OPC UA model and the implemented data structures used to store this information.
The OPC UA Address Space Model consists of an undirected graph of nodes which are connected using typed references. Beside the type information references contain additional meta information like IsAbstract and Symmetric. Also references that have a direction from the OPC UA point of view (Symmetric=true), can be browsed in reverse direction, so from the graph point of view this is still a undirected edge. It is also important to note that this graph can contain cycles.
Important properties of the graph:
Important properties made by the SDK:
This can be best shown if the following simple node model:
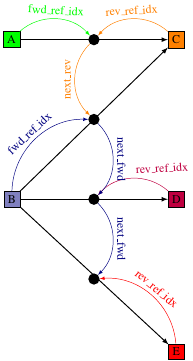
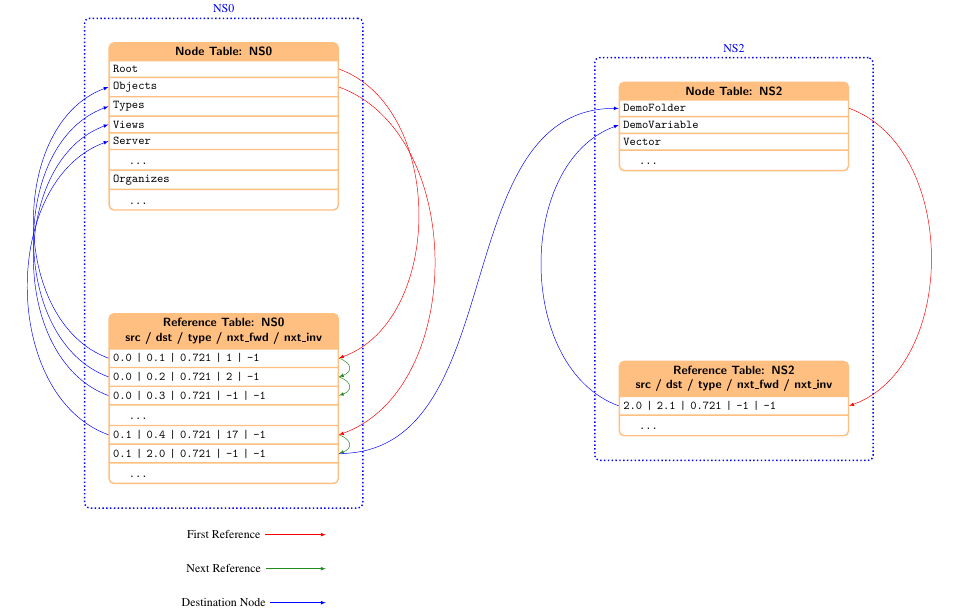
Nodes and references are allocated in object pools which are managed by ua_addressspace. For each namespace index there exists a separate pool. This allows to eliminate redundant nsidx information.
A pool can be seen as an array (or table) of a structure (e.g. node or reference). No pointers are used, instead indices into those table entries create the "pointers" to other elements. For this reason the tables are address independent and relocatable in memory.
It is technically possible to store those tables in memory mapped files, or to generate C containing the table information, like it is done by xml2c.
When loading a binary file the tables are created at runtime with information from the file, thus the tables exit in RAM.
Binary address space files are very compact files compared to their XML counterparts and way more efficient to load. This means it uses just a fraction of the memory required for XML parsing and it is much faster. The file format is described in OPC UA Binary File Format.
The possible command line arguments can be listed by calling the tool with the option -h as usual: ./xml2bin -h. The help also gives you one simple example.
Important Notes:
-i select this namespace to be exported. The namspaces are normally numbered that way:-i. It will print the namespace table.Important here is the SDK Index, which is the index that will be used in the SDK and must be unique. The columne XML Index, shows the numeric index used in the XML file which is not unique across files. Prefix is used only for code generation. URI is the unique URI of the information model. Instead of selecting the SDK Index using -i you can also select the model using the option -u and the URI string.
At runtime you can load binary files simply calling ua_addressspace_load_file. See Sensor Model Server for an example.
The purpose of generating C code is to reduce the memory requirements of OPC UA Server applications. UA address space can get huge and because they contain a lot of string information, the required memory is too big for many embedded applications.
By generating C code we can move the address space from RAM into ROM, thus reducing the RAM usage.
Note that this is only true for systems that can run code from ROM (e.g. flash memory). Systems that copy all data to RAM before execution cannot benefit from this solution for obvious reasons.
The process data (value attribute) is separated from other node information. This allows to connect dynamic data with static nodes. However it is also possible to define values already in the XML file for constant information like input- and output-arguments of a method.
xml2c generates a static values store for the variables which contain a value in the XML file. The generated node is connected with the correct store entry at compile time by assigning the according store index and value index.
For all other variables an alternative store index is assigned that you can specify as an command line argument. At runtime you need to create any kind of value store and register it for this store index. This way you can connect static nodes with dynamic data.
See Lesson 2: Custom Provider with Value Stores for a detailed explanation of value stores.
If the whole address space is generated the table model just works as in RAM, because everything is index based. The only difference is that you cannot modify the address space, because it consists of C constants.
There is the typical use case that you have a compiled-in static address spaces for type models like NS0 (OPC UA) and other models like e.g. DI or PLCOpen, but you need to add also nodes at runtime (e.g. instance of such types).
This leads to the problem that you need to add references from compiled-in static nodes to nodes that exist in RAM. But the node tables and reference tables of the source nodes are constants, so this is not possible.
To fix this problem we created the so-called placeholder concept. A static address space can contain - in addition to the static node table and reference table - a further dynamic reference table with placeholder references. Nodes which should be extendable at runtime contain a placeholder reference as last element in the reference list. All the indices from nodes to references, and from the last static reference to the place holder reference are static, and don't need to be changed. The placeholder reference does not have a type or destination node, which marks it as a placeholder. When adding the reference from a static node to a dynamic node the placeholder reference becomes a real reference which points to the newly created dynamic node.
The following image illustrates how the static node "Objects", which contains already a reference to the static node "Server", is connected to the dynamic node "DemoFolder" from NS2 using such a placeholder.
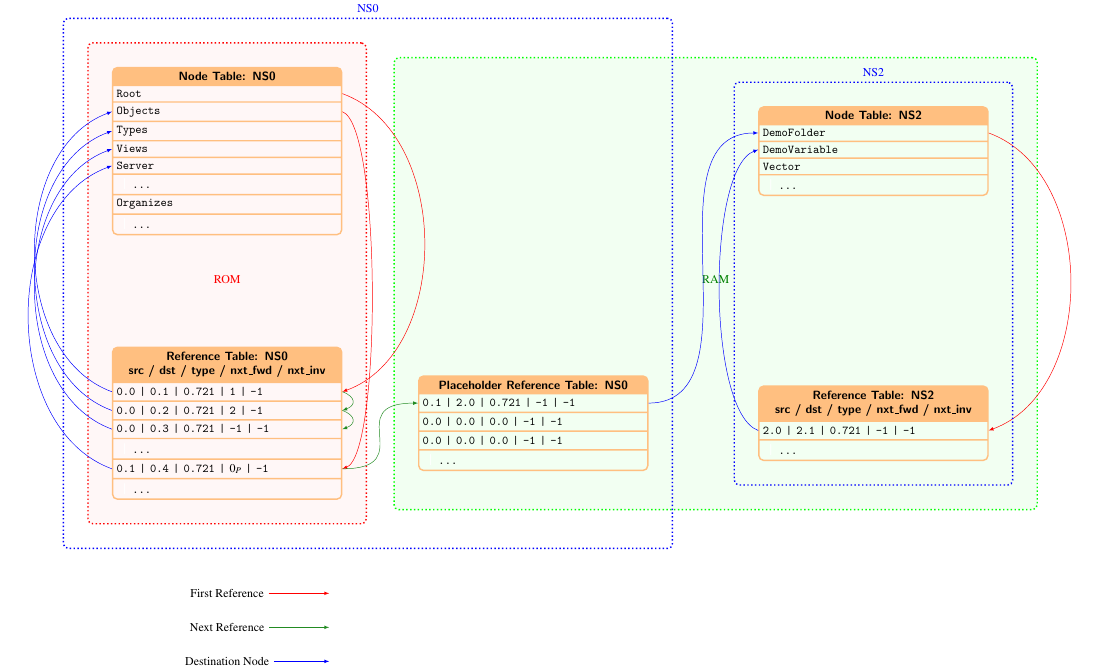
Limitations: When adding references via placeholders this works only for outgoing (forward) references, not for incoming (inverse references). This means if you add e.g. a HasTypeDefinition reference to a static type, this will not be added to the type's inverse reference list. Thus reverse browsing of a type to get all the instances will not work. Because this is not a typical use case must people can live with this limitation.
Calling xml2c works very similar to invoking xml2bin, but requires some additional arguments.
Example:
$> mkdir -p output $> ./xml2c -n di -i2:di:12 -o output Opc.Ua.NodeSet2.xml Opc.Ua.Di.NodeSet2.xml
The main difference to xml2bin is that this tool not only generates the address spaces, but also C Header and Source files for all types defined in the information model. It also creates a CMakeLists.txt which will create a complete C library for that information model. If the model contains datatypes this will get registered automatically at the SDK's generic encoder/decoder, so that the SDK is able to encode/decode those datatypes. This works out-of-the-box, the only thing you need to to in your application is to linked against this library and call the generated function <prefix>_register_static_addressspace.
Options:
| Option | Description |
|---|---|
| -n | Specifies the library name used in the generated CMakeLists.txt |
| -i | Selects the SDK Index to export, the prefix, and the alternate store index |
| -o | Selects the output folder where the source files should be generated. |
The example command above will generate the following files.
The table below describes the purpose of the different generated files.
| File/Folder | Description |
|---|---|
CMakeLists.txt | CMake project to compile the 'DI' library. |
di/ | Folder containing all sources for the DI model. |
ns2.c | The constant address space tables. |
identifier.h | Defines with NodeId identifiers. |
type_* | Type table code for generic encoder/decoder. |
*type.[c,h] | Generated code for DI datatypes. |
The library will contain all the code to for datatypes and the generic encoder/decoder, but does not include ns2.c! This will needs to be included directly by your provider code as shown in the example Sensor Model Server.
The library gets linked with the application and can be used with static address spaces as well as with dynamic address spaces loaded from file.
Because xml2c can generate the C datatypes based on the UA type information and the according type tables for the generic encoder/decoder it makes it very easy for to use custom datatypes.
All you need to do is:
#include the generated type_table.h header fileUA_TYPE_TABLE_SORTING_NONE to ua_type_table_register_const_table. The function will check the table and detects sorting automatically.Of course the application needs to link against th generated information model library, to be able to use the generates types and type tables.
Note: This works with dynamic and static type systems.
Limitations: Currently only numeric TypeIds are supported.