 |
High Performance OPC UA Server SDK
1.1.1.177
|
|
High Performance OPC UA Server SDK
1.1.1.177
|
One of the biggest challenges of OPC UA for embedded devices is the memory consumption of the huge server address space.
Already the standard OPC UA namespace with namespace index 0 contains 1755 nodes, and over 4000 strings with over 80K of pure string data.
One possibility to reduce this is eliminating all optional nodes, but more important is a good concept which allows huge address spaces without consuming too much memory. In this SDK we've put a lot of effort in reducing the memory consumption of the UA address space, without sacrificing important functionality.
We developed a special table based node storage where each table consists of an array of node entries, which is defined in nodestorage.h. Our definition of the nodestorage was optimized to reduce the amount of data being stored and eliminates redundant information like e.g. nsidx (each nodeid in one namespace has the same nsidx). Even more important is that we defined a Node API which encapsulates the node storage. All other SDK parts only access the node data via that Node API, so the internal storage can be tuned to your needs, without breaking the interface. High level functions like Browse or TranslateBrowsePathToNodeIds work on this API.
The general graph like address space is based on the node table and reference table. The node table contains all BaseNode attributes, and the reference table contains all references which connect those nodes. These two tables alone are enough to implement Browse functionality. The nodes are compact and lie side by side in memory in a optimized way (cache locality), and sorted in that order as they have to be traversed during a Browse operation.
Nodeclass specific data like e.g. for variables are located in a separate variable table and is referenced by an index from the node table, so variable specific data can be accessed with a single indirection.
Nodes get indexed by an hashtable which is also an optimized implementation specific to OPC UA. In addition Registered NodeIds exploit the table based nature of our address space concept by simply using the table index as a Numeric NodeId.
The SDK allows multiple instances of our address space implementation. For every namespace you create a new address space, which together form the complete server address space. For each address space the nsidx is well known which allows to eliminate redundant nsidx information in the nodes. For each address space you can configure the size constraints and if the address space is created dynamically in RAM or if it is compiled into the application.
One of the most important features of this SDK is that we can generate C code for address space tables, which consists of const data arrays and so can be compiled into the application's firmware. Thus these data can completely reside in ROM and do not require any RAM.
The descriptions attribute is optional, so we allow to disable this attribute completely. This way the node entries get a little smaller and you can safe a lot of string data.
Normally values come from the underlying process, so we avoid the overhead of storing generic OPC UA Variant values in the address spaces. Connecting data is done more efficiently by using our value store interface, which allows also static value stores which can be compiled into the firmware for constant data. The example Lesson 2: Custom Provider with Value Stores shows how to use such value stores.
When creating nodes all string data is added to a string table. This string table eliminates multiple occurrences of the same string, thus reducing the memory consumption for those strings.
When creating nodes dynamically in RAM the strings get indexed by an hashtable to be able to quickly lookup an existing string. The string data itself is encapsulated by a so called hashstring, which stores a reference counter for the string, the string length and the pointer to the string data itself. The hashstring also contains a next pointer to handle hash collisions by using a single linked list. The hashstring itself also has some overhead, but this pays well when the strings are longer or you have multiple copies of the same string.
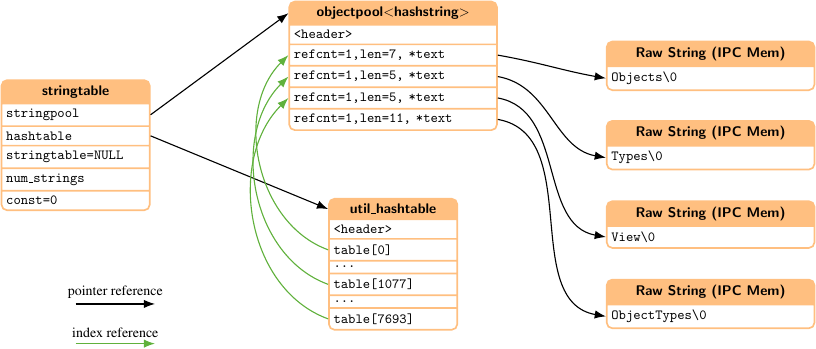
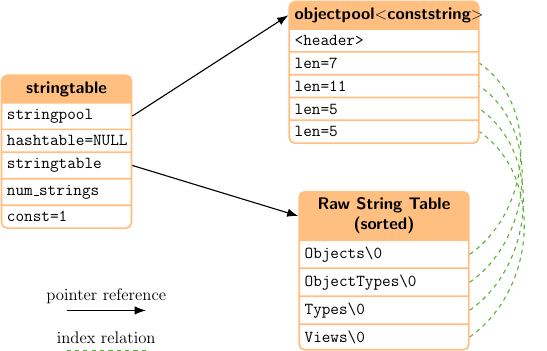
When using a statically generated address spaces also the stringtable gets generated as const data, which gets compiled into your application. In this case strings cannot be added at runtime to this table and we can further optimize the implementation. The raw strings get generated as a string array which is sorted by the NodeId. This way we can completely omit the hashtable and do a binary search instead. Also the hashstring gets replaced by conststring, which only holds the string length. The reference counter and next pointer are not required in this context. The indices of the objectpool are always synchronous with the stringtable indices.
The SDK contains an own XML parser which could be used to parse XML Nodeset Files, or any other XML file. The XML parser is designed to be portable and uses special techniques to reduce memory consumption while parsing XML, but parsing XML Nodeset files is way more complicated then just parsing XML, due to the complexity of the Nodeset schema. The design of the schema requires iterating of the DOM multiple times, namespaces can be spread over multiple files, one file can contain multiple namespaces, values may have multiple encoding variants, etc.
The complexity is not only inefficient, it is also a security risk, because there is a high potential of errors which could lead to application crashes.
Therefor we created xml2bin tool which implements the logic of parsing XML Nodeset files and create a compact binary file, which is easy to load at runtime. This tool can be integrated into the engineering process, so that during the Download process (e.g. of a PLC program), the binary file with the UA address space is downloaded instead of huge XML files.
The binary file was designed to be read in one pass and consumes only a fraction of code size and memory. Also the file size could be reduced a lot compared to XML.
The following tables shows a file size comparison of typical information models:
| Model | XML File Size | Binary File Size | Ratio |
|---|---|---|---|
| Opc.Ua.NodeSet2.xml | 1.6 MB | 131 KB | 8 % |
| Opc.Ua.Di.NodeSet2.xml | 95 KB | 13 KB | 13 % |
| Opc.Ua.Plc.NodeSet2.xml | 19 KB | 1.9 KB | 10 % |
| Opc.Ua.AutoID.NodeSet2.xml | 277 KB | 19 KB | 7 % |
The SDK provides support for binary address space files. So if your system provides a file system you can enable file support and you are able to load address spaces at runtime from these binary files.
Note that it does not make sense to compile binary files into the application. A binary file gets de-serialized when loaded and all the data is copied into RAM. So if want to compile an address space into the application, the generated C code is the better option, because then the tables can be directly be used without copying them into RAM.
The SDK also allows to generate C code of information models that you can comile into the application. This is useful for sensor applications with static address spaces and to compile-in type systems like e.g. UA, DI, and PLCOpen, so that you only need to hold the instances in RAM, but not the types. See Address Space Generation for more information.
If you want to define your own information models you can use our UaModeler application which ships with all of our SDKs. This tool allows to export the standard UA XML file format which then can be fed into xml2bin and xml2c. See Address Space Generation for more information.